Linux上のPHPのstrcmpで🍣と🍺を引数にするとint(5888)になる
TOP > てきとうにこらむ > プログラミング日記 > Linux上のPHPのstrcmpで🍣と🍺を引数にするとint(5888)になる

寿司(Sushi)とビール(Beer)について
寿司とビールのstrcmpについて
何故か、Linuxでは次のコードが5888という値を返す。3v4lでも同じだった。
var_dump(strcmp("🍣", "🍺"));
int(5888)
Macだと23を返すし、🍣と🍺の差は確かに23(0x17)しかない。なぜ、5888なんて値を返すのだろう。
考察
5888という値は、10進数である。なぜそんな謎の値なのかわからなかったのだけど、現代のコンピューターで10進数としてみても、そんなに意味はないのではないかということで、16進数に変換してみることにした。
$ sapi/cli/php -r 'var_dump(dechex(5888));'
string(4) "1700"
つまり、5888の16進数では、0x1700であり、バイト列の違いによるものなのかな?ということがわかってきた。
strcmpのコードは https://github.com/php/php-src/blob/php-7.3.2/Zend/zend_builtin_functions.c#L591 からはじまる、次のコード。
ZEND_FUNCTION(strcmp)
zend_binary_strncmpが返り値となっているので、その実装を見る。それは https://github.com/php/php-src/blob/php-7.3.2/Zend/zend_operators.c#L2698 で見られるが核心部分は次の2721行目のmemcmpである。
retval = memcmp(s1, s2, MIN(length, MIN(len1, len2)));
この返り値がretvalであるので、この値が0x1700という値を返すのだろう。ということはLinuxでどういう実装がされているかということになるか。
memcmpのアルゴリズム
memcmpのアルゴリズムを調べよう。memcmpのmanには次のようにある。
0 でない値の場合、 s1 と s2 で値が異なった最初のバイトの値の差で符号は決定される (バイトは unsigned char で解釈される)。
単純にs1とs2を各バイト比較して、差が出たらそのままかえすというアルゴリズムなのだろう。
MacとLinuxとで、memcmpが違うという最小のコードを調べて、cmp.cとした。
#include <stdio.h>
#include <string.h>
#include <unistd.h>
int main(void) {
char s1[2] = {0xF0, 0x70};
char s2[2] = {0xF0, 0x80};
int result;
result = memcmp(s1, s2, 2);
printf("%d\n", result);
return 0;
}
F0 70とF0 80とをmemcmpで比較するコード。Macだと-16(0x10)と表示され、Linuxだと-4096(0xFFF0)と表示される。
アセンブリを調べる
memcmpのアルゴリズムは、差を求めるものだから、MacとLinuxとで何かが違うというものではないと思う。ということで、アセンブリを読んでみることにした。x86のアセンブリは初めて読むので、違うところがあるかも。
cmp.cを-Sオプションで実行すると、アセンブリコードが出てくるので、それをcmp.Sという名前で保存させてそれを読んで見る。
$ gcc -S -o cmp.S cmp.c
Macのgccコマンドでコンパイルをすると、.asciiとして確保するようだ。というか、LLVM GCCというものだからなのか、アセンブリコードが比較的にきれいと感じる。
.section __TEXT,__text,regular,pure_instructions
.macosx_version_min 10, 13
.globl _main ## -- Begin function main
.p2align 4, 0x90
_main: ## @main
.cfi_startproc
## %bb.0:
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset %rbp, -16
movq %rsp, %rbp
.cfi_def_cfa_register %rbp
subq $32, %rsp
leaq L_.str(%rip), %rdi
leaq -8(%rbp), %rsi
leaq -6(%rbp), %rax
movl $0, -4(%rbp)
movw l_main.s1(%rip), %cx
movw %cx, -6(%rbp)
movw l_main.s2(%rip), %cx
movw %cx, -8(%rbp)
movl $2, %edx
## kill: def %rdx killed %edx
movq %rdi, -24(%rbp) ## 8-byte Spill
movq %rax, %rdi
callq _memcmp
movl %eax, -12(%rbp)
movl -12(%rbp), %esi
movq -24(%rbp), %rdi ## 8-byte Reload
movb $0, %al
callq _printf
xorl %esi, %esi
movl %eax, -28(%rbp) ## 4-byte Spill
movl %esi, %eax
addq $32, %rsp
popq %rbp
retq
.cfi_endproc
## -- End function
.section __TEXT,__const
l_main.s1: ## @main.s1
.ascii "\360p"
l_main.s2: ## @main.s2
.ascii "\360\200"
.section __TEXT,__cstring,cstring_literals
L_.str: ## @.str
.asciz "%d\n"
.subsections_via_symbols
Linux上のgccでは、movbでレジスタへ値をコピーすることで初期化しているようだ
.file "cmp.c"
.section .rodata
.LC0:
.string "%d\n"
.text
.globl main
.type main, @function
main:
.LFB0:
.cfi_startproc
pushq %rbp
.cfi_def_cfa_offset 16
.cfi_offset 6, -16
movq %rsp, %rbp
.cfi_def_cfa_register 6
subq $32, %rsp
movb $-16, -16(%rbp) # (%rbp -16)へ0xF0をコピーする
movb $112, -15(%rbp) # (%rbp -15)へ0x70をコピーする
movb $-16, -32(%rbp) # (%rbp -32)へ0xF0をコピーする
movb $-128, -31(%rbp) # (%rbp -31)へ0x80をコピーする
leaq -32(%rbp), %rcx # 0x70F0を%rcxへコピーする
leaq -16(%rbp), %rax # 0x80F0を%raxへコピーする
movl $2, %edx
movq %rcx, %rsi # %rsiはmemcmpの第一引数
movq %rax, %rdi # %rdiはmemcmpの第二引数
call memcmp # 故にmemcmpのアルゴリズムでは0x70F0 - 0x80F0となる
movl %eax, -4(%rbp)
movl -4(%rbp), %eax
movl %eax, %esi
movl $.LC0, %edi
movl $0, %eax
call printf
movl $0, %eax
leave
.cfi_def_cfa 7, 8
ret
.cfi_endproc
.LFE0:
.size main, .-main
.ident "GCC: (Debian 4.9.2-10) 4.9.2"
.section .note.GNU-stack,"",@progbits
いろいろと読んでみたところ、どうやら、movbの部分が初期化している部分で、それをcall memcmpへ渡すためにいろいろやっているということのようだ。
コメントを書いてみてわかったことは、70 F0と後ろから8ビットずつ挿入していき、80 F0と後ろから8ビット挿入したものを、leaqで64ビット%rcxと%raxへ移しているということだった。
ということは、%rcxは0x70F0で、%raxは0x80F0となり、その後%rcxは%rsiレジスタ(memcmpの第一引数)へ、%raxは%rdiレジスタ(memcmpの第二引数)へ移動し、それをmemcmpへ送って比較させているということのようだった。
memcmpでは、0x70F0と0x80F0との差を求めることになったので、0xFFF0という値が返ってきたようだった。
それでは、gdbを使って、渡された引数がどういう値になっているか確認しよう。-gフラグを付け直してコンパイル。
ちなみに、gdbはGDB dashboardを使っている。
$ gcc -g -o cmp cmp.c
$ gdb ./cmp
>>> b main
Breakpoint 1 at 0x400585: file cmp.c, line 6.
>>> run
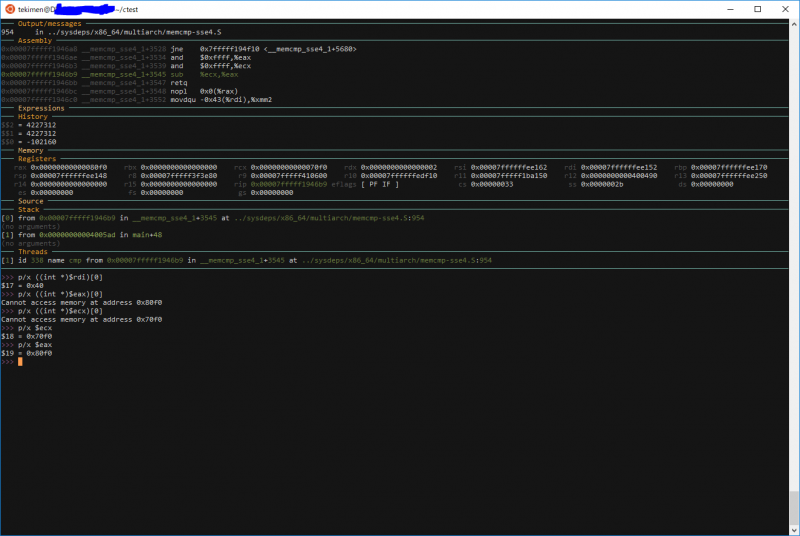
11行目まで進め、memcmpの行でstep。memcmpのアセンブリ部分まで入るので、その部分で$rcxと$raxを調べてみる。
>>> print/x ((char*)$rcx)[0]
$19 = 0xf0
>>> print/x ((char*)$rcx)[1]
$20 = 0x80
>>> print/x ((char*)$rax)[1]
$21 = 0x70
>>> print/x ((char*)$rax)[0]
$22 = 0xf0
charでキャストすると、その順番通りになることが確認できた。
>>> print/x ((long int*)$rax)[0]
$32 = 0x4070f0
>>> print/x ((long int*)$rcx)[0]
$33 = 0x7ffffffe80f0
ただ、$raxと$rcxとが、なぜ0x4070f0と、0x7ffffffe80f0なんて値で、どうやって引き算しているのかという部分が謎ではある。流石にどうして0x4070f0と0x7ffffffe80f0となっている理由まではちょっとわからない。
アセンブリをそのまま走らせると、以下のようなニーモニックが出現した。
0x00007fffff1946ae __memcmp_sse4_1+3534 and $0xffff,%eax
0x00007fffff1946b3 __memcmp_sse4_1+3539 and $0xffff,%ecx
0x00007fffff1946b9 __memcmp_sse4_1+3545 sub %ecx,%eax
0x00007fffff1946bb __memcmp_sse4_1+3547 retq
0x00007fffff1946bc __memcmp_sse4_1+3548 nopl 0x0(%rax)
0x00007fffff1946c0 __memcmp_sse4_1+3552 movdqu -0x43(%rdi),%xmm2
つまり、それぞれのレジスタに保存されている値は、最終的に0xffffでマスクされているので、調べる値は正しく0x70f0と、0x80f0になって、それを0x70f0 - 0x80f0とになるようだ。
結果、%eaxに0xfffff000(-4096)が値として入るわけだ。
結果として
結局の所、PHPもPHPのstrcmp関数も何も問題がなくって、エンディアンの問題だったようだ。もちろん、🍣と🍺の文字自体にもこの内容では問題がなかった。(MySQLの寿司ビールも違う話)
memcmpの挙動として、Linux(gcc)では、差を求めるときに上位バイトと下位バイトとが入れ替わるようだが、これは環境依存だし私は全くアセンブリも、glibcなどもわかっていないので、違うことを言っているかもしれない。
参考
- X86アセンブラ/データ転送命令 - Wikibooks
- X86アセンブラ/GASでの文法 - Wikibooks
- 2進数、8進数、10進数、16進数相互変換ツール 恥ずかしながら、符号付きの16進数がわからなかったので計算に使った。
- 遭遇したmemcmpのアセンブリ…だと思う