CPythonでのUTF-16のエンディアンがCPUアーキテクチャ依存もしくは不定になっている #python
TOP > てきとうにこらむ > プログラミング日記 > CPythonでのUTF-16のエンディアンがCPUアーキテクチャ依存もしくは不定になっている #python


CPythonでのUTF-16の挙動について
CPythonでUTF-16のエンディアンが未指定かつBOMもないとき、環境によってエンディアンが異なるという問題に遭遇しました。
コード
簡単なコードでこういうのです
b"ab".decode("UTF-16")
このとき、BOMもなく、UTF-16の後ろにLEもBEもない場合に、環境(CPUアーキテクチャ)によってはエンディアンが異なるために、異なるコードポイントを指します。
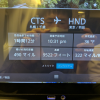
x86_64環境では慢(U+6162)、aarch64環境では扡(U+6261)が表示されることを確認しました。なお双方ともLinuxで試しています(aarch64ではmacOSでも試しています)
もしかするとバイトオブジェクトの問題かもしれませんが、ちょっとCPythonの専門家ではないため、調査をお願いしたいと思い、issueを立てさせていただきました。
https://github.com/python/cpython/issues/128571
Unicodeではどう定義されているのか
Wikipediaにあるとおり、BOMもなく上位でのエンディアンでの指定がない場合にはビッグエンディアンになるとなっています。そのため、慢(U+6162) が正しいと考えられます。
少なくとも、エンディアンが不定でアーキテクチャによって変わるのは疑問に思いました。
参照元
https://www.unicode.org/versions/Unicode16.0.0/core-spec/chapter-3/#G28070
The UTF-16 encoding scheme may or may not begin with a BOM. However, when there is no BOM, and in the absence of a higher-level protocol, the byte order of the UTF-16 encoding scheme is big-endian.
というわけであとは任せた
PHPでmb_detect_encodingがUTF-16に判定されると指摘されたIssueを元に遊んでいたのですが、Pythonでこうなるとはという感じでした。なお、元Issueでは漢字が出てきたのが拒絶反応だったのか「そんなことは聞いてない」とキレられました。
https://github.com/php/php-src/issues/16566
ついでだからYouTubeショートも見てくれると嬉しいな